
画像生成AIとは?
そもそも画像生成AIって何でしょうか?
画像生成AIはジェネレーティブAIの一つで、コンピューターが学習した知識やルールに基づいて、人工的に画像を生成するAIのことです。
大量の画像を学習データとして使用してその中からパターンや特徴を学習し、それを基に新しい画像を生成します。
近年、技術的ブレイクスルーから爆発的に性能が向上し、写真や人間が描いたイラストと生成画像の区別がつかないレベルにまで進化を遂げました。
以下のような本ブログのアイキャッチも全て私が画像生成AIで生成したものです。









代表的な画像生成AIサービス
2023年現在、画像生成AIを用いた代表的なサービスを表にまとめました。
| サービス名 | 利用方法 | 価格 | 特徴 |
| Midjourney | Discord | 30$/月 | 25回までは無料。アーティスティックな絵柄が得意。 |
| nijijouney | Discord | 30$/月 | Midjourneyの二次元イラスト特化版。日本語利用可能。 |
| DALLE-2 | ブラウザ | 115クレジットで15$ | フォトリアル調が得意。画像生成AIの元祖火付け役。 |
| Novel AI | ブラウザ | 15$/月 | 二次元イラストが得意。Stable Diffusionをベースに開発。 |
| Stable Diffusion | PCローカル | 完全無料 | 内部モデルを変更することでフォトリアル調もイラスト調も様々な絵柄を出力可能。枚数制限がなく完全に無料。PCスペックに依存するが、良い環境では生成速度が最速。現状、最も高品質。 |
この中で私が1番オススメするのがStable Diffusionです。
何枚画像を生成しても完全無料で使用できます。さらに現状で最も生成速度が速く、最も機能性が高く、最も高品質な画像を生成できます。
他のAIサービスと違ってPCの知識が必要だったり、導入が多少手間だったりと少し敷居の高さはありますが、今本気で画像生成AIを極めたいなら、Stable Diffusion一択です!
StableDiffusionはオープンソース?
StableDiffusionはソースコードが無償公開され、利用・改変・再配布が自由に許可されているオープンソースソフトウェアです。
「オープンソース?なんでそんなに気前がいいの?」と思うかもしれませんね…。
その理由は、StableDiffusionを開発した会社Stability AIが「一部の大企業や個人がAIを独占することは健全ではなく、AIは世界中の人々が平等にアクセスできるようになるべき」という理念に基づいて行動しているからなんです。応援したくなるピュアでカッコいい理念ですよね!
StableDiffusionの優位性
StableDiffusionがオープンソースであることのメリットは4つあります。
- 完全無料で利用できること。
画像生成の枚数に上限はなく、かかるのはPCの電気代だけです。 - ローカル環境で実行できること。
ある程度PCのスペックは要求しますが、通信遅延や制限速度などの制約がないため最速で快適に画像生成ができます。 - 大人向けな画像も生成できること。
StableDiffusionは18禁セーフフィルターを解除できるので、アングラな画像も生成できます。 - 関連ツールやモデルの開発速度が速いこと。
誰もがソースコードにアクセスして自由に改良できるので、有志の開発者がより高機能なツールを作ったり、ハイクオリティなモデルを配布したりしてくれています。
世界中の人間が開発者になれるので、営利目的の企業が開発する速度をはるかに上回って毎日のように新しいアップデートがされているのです。
StableDiffusionの機能
StableDiffusionには、主に2つの機能があります。
- Text to Image(t2i):プロンプトと呼ばれる呪文を与えて、呪文に沿った画像を生成
- Image to Image(i2i):画像データを入力してそれに似た画像を生成
今回はText to Imageについて具体的に説明していきましょう。
プロンプトにはポジティブプロンプトとネガティブプロンプトの2種類があり、ポジティブプロンプトは作ってほしい画像を指定するもので、ネガティブプロンプトは逆に「こういうのは作らないで」と指示するものです。
早速次のような呪文を与えてみます。
| Positive Prompt | masterpiece, best quality, masterpiece, asuka langley sitting cross legged on a chair |
| Negative Prompt | lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts,signature, watermark, username, blurry, artist name |
この呪文はハローアスカベンチマーク(Hello Asuka Benchmark)と呼ばれるベンチマーク用の呪文で、新世紀エヴァンゲリオンのヒロインである惣流・アスカ・ラングレーに似た女の子が出力されます。
作られた画像は以下の通りです。StableDiffusionのモデルを変えると、同じプロンプトでもいろんな雰囲気の絵柄で出力できることが分かりますね!



StableDiffusionWebUI (AUTOMATIC1111)って何?
StableDiffusionWebUIは、AUTOMATIC1111氏が開発したStableDiffusionをブラウザ上で簡単に操作できるツールです。
以下のようなUIで、直感的に操作が可能です。
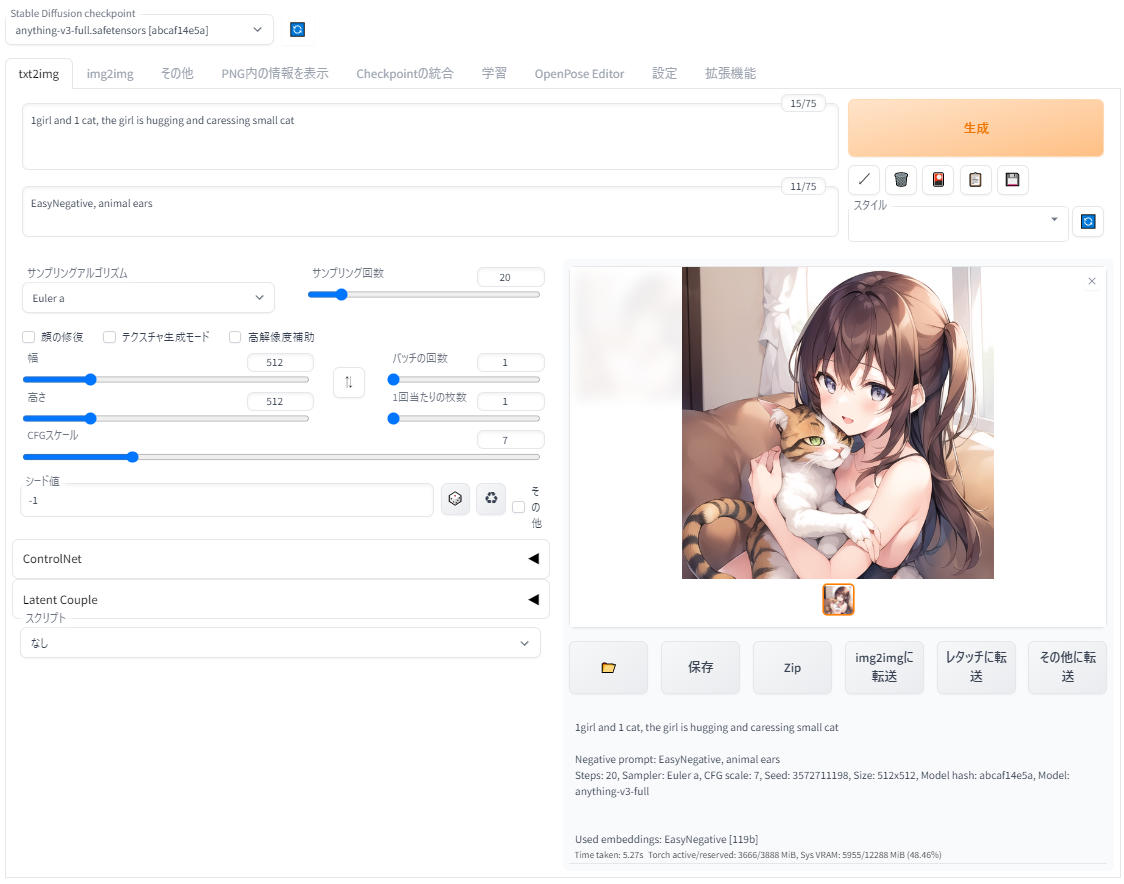
このツールはプログラムの知識がない初心者でも簡単に扱えて、頻繁にアップデートされているため機能性・拡張性がかなり高く、ローカル環境で画像生成を行いたい人にとっては決定番といえるツールです。
以下の記事で導入方法を詳しく解説しています。さっそく導入して、StableDiffusionのすごさを体感してみてください!

ジェネレーティブAIの明るい未来
ジェネレーティブAIは今後も進化を遂げていきます。多くの研究者が今研究しているテーマとしては、AIモデルのマルチモーダル化が挙げられます。
現在のAIモデルはテキストだけ、画像だけ、音声だけなど学習データが1種類(モノモーダル)で学習しているものが主流です。
しかし、今後はテキスト・画像・音声・動画・触覚データ・運動データなど五感に関わるあらゆるデータを一つのモデルで扱えるマルチモーダルモデルが登場すると言われています。
➡もうすでにマルチモーダル対応のAIモデル GPT-4が登場しています。AIの発展は日進月歩ならぬ秒進日歩の世界です。毎日驚かされています…。
マルチモーダル化により、物の意味や概念がより人間に近い形で理解できるようになり、汎用人工知能(人間ができる仕事は全てこなせる万能の願望器、AGI)の開発に近づくとされています。


楽しさ・嬉しさ・感動といった今まで人間が特権的に持っていた概念すらも、コンピュータは真の意味で理解し扱えるようになるはずです。
そうなれば、コミック・小説・ドラマ・映画・アニメ・ゲームなど、私たちが熱狂したコンテンツの概念を塗り替えるような、クリエイティブでエキサイティングな生成物がAIによって無限に量産されるでしょう。
ジェネレーティブAIはまだまだ始まったばかりですが、この先に待ち受けている世界は私たちの想像を絶する驚きに満ちたものになるでしょう。
このビックウェーブに乗り遅れないよう、本ブログでも先端技術を紹介していきたいと思います!
今後ますます、ジェネレーティブAIの開発と発展に目が離せません!!
👇AI界のインフルエンサー”深津”様の本。画像生成AIを体系的に学びたい方にオススメです。



コメント